Hadoop使用了master/slave的集群架构。master包括了NameNode和ResourseManager两个重要的Hadoop节点。所以master是一种非常重要的节点。一定要保证master的硬件资源是最好的。
但是,即使是最好硬件,最稳定的机器也可能出现问题,而master又是如此重要,所以我们需要一种高可用架构,使得即使master坏掉,整个集群也能迅速恢复工作。
Hadoop 2.x引入了高可用的集群架构,这个架构方案是针对master单点故障导致整个集群奔溃提出的解决方案。
架构的关键就是配置多台master主机,形成一个master集群。一个master是真正工作的,另外的master备份工作master的数据。一旦工作master宕机,其余的master能够马上进入工作状态。
这涉及到两个master状态:Active和Stand-by。表示工作状态和等待状态。
那么我们如何维护这个master集群,如何实时获取、修改它们的状态呢?这就可以使用ZooKeeper对它们进行管理。
我们可以让每个master主机保持一个Zookeeper临时节点。当Active的临时节点消失(要么网络差,要么这个NameNode奔溃了),就马上选出一个新的master。
为了保持高可用性,需要保证多个master保持同步。所以我们还需要Journal Node(s)节点。
拿NameNode来说,所有NameNode节点都保持和Journal Node(s)节点的通信。当Active NameNode更新了元数据信息,会把日志修改记录发给Journal Node(s),Stand-by NameNode(s)会从Journal Node(s)上读取这些更新的edits文件或者是edits的更新记录。随后将日志变更保存在自己这里。可见这是一种热备份(注意区别于SecondaryNameNode,是冷备份)。
如果Active NameNode挂掉了,被选为新的Active Namenode的Stand-by NameNode会马上从Journal Node(s)处更新一遍edits。确保此时的元数据和Active的一致。
ResourceManager也使用Journal Node(s)来保证元数据的热备份,它可以和NameNode共用Journal Node(s)。
以上架构需要多个NameNode、ResourseManager、DataNode、NodeManager、Zookeeper、Journal Node(s)等,需要大量的机器。如果经济情况不好,可以做适当的合并。例如把NameNode和Zookeeper放在一起。
准备集群
下面以6台虚拟机(CentOS 6.5)作为示例。
集群的架构策略如下:
- master1
- Zookeeper
- NameNode (active)
- ResourceManager (active)
- master2
- Zookeeper
- NameNode (stand-by)
- master3
- Zookeeper
- ResourceManager (stand-by)
- slave1
- DataNode
- NodeManager
- JournalNode
- slave2
- DataNode
- NodeManager
- JournalNode
- slave3
- DataNode
- NodeManager
- JournalNode
我们先准备一台纯净的虚拟机,随后拷贝虚拟机即可。按照以下的步骤操作:
准备jdk,这里使用1.8_65版本,具体步骤不再演示。
1
2
3
4
5
6
7
8
9
10
[root@master1 ~]# java -version
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
[root@master1 ~]# javac -version
javac 1.8.0_65
[root@master1 ~]# echo $JAVA_HOME
/usr/develop/jdk1.8.0_65
[root@master1 ~]# echo $JRE_HOME
/usr/develop/jdk1.8.0_65/jre
关闭防火墙(真实环境请配置iptables,不要关闭)
1
2
3
4
5
[root@master1 ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@master1 ~]# chkconfig iptables off
配置主机名以及hosts文件
1
2
3
4
5
6
7
8
9
[root@master1 ~]# vim /etc/hosts
127.0.0.1 localhost
::1 localhost
192.168.117.52 master1
192.168.117.53 master2
192.168.117.54 master3
192.168.117.55 slave1
192.168.117.56 slave2
192.168.117.57 slave3
安装Hadoop,不进行配置。加上HADOOP_HOME环境变量,将HADOOP的bin和sbin加入PATH
1
2
3
4
5
6
7
8
9
[root@master1 hadoop-2.7.1]# echo $HADOOP_HOME
/usr/develop/hadoop-2.7.1
[root@master1 hadoop-2.7.1]# hadoop version
Hadoop 2.7.1
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a
Compiled by jenkins on 2015-06-29T06:04Z
Compiled with protoc 2.5.0
From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a
This command was run using /usr/develop/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar
随后,关机,克隆5台虚拟机。
克隆完成之后,根据上面的方案修改每台主机的配置。注意需要修改/etc/sysconfig/network下的主机名和/etc/sysconfig/network-script/ifcfg-eth0下的ip地址。
下面演示修改master2的步骤,其余都是类似的:
配置克隆机的网卡(否则会使用eth1)
1
2
[root@master2 ~]# vim /etc/udev/rules.d/70-persistent-net.rules
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:b7:b0:19", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
配置host
1
2
3
4
[root@master2 ~]# vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master2
NTPSERVERARGS=iburst
配置ifcfg-etho0
1
2
3
4
5
6
7
8
9
10
[root@master2 ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
BOOTPROTO=static
IPADDR=192.168.117.53
NETMASK=255.255.255.0
GATEWAY=192.168.117.2
ONBOOT=yes
TYPE=Ethernet
IPV6INIT=no
DNS1=192.168.117.2
其余克隆机的配置步骤和上面类似,注意需要配置为自己的ip和host。
确保各个虚拟机之间能够ping通后,给这6台虚拟机配置ssh免密登录。
6台虚拟机都需要生成公钥和私钥。并且要发送到其余的虚拟机上。
下面是在master1上配置ssh免密,然后发送到其余5台和自己上。每台的操作都和master1类似:
1
2
3
4
5
6
7
[root@master1 ~]# ssh-keygen
[root@master1 ~]# ssh-copy-id -i root@master1
[root@master1 ~]# ssh-copy-id -i root@master2
[root@master1 ~]# ssh-copy-id -i root@master3
[root@master1 ~]# ssh-copy-id -i root@slave1
[root@master1 ~]# ssh-copy-id -i root@slave2
[root@master1 ~]# ssh-copy-id -i root@slave3
确保每台机器之间能够正常免密登录之后,准备工作就完成了。
为master安装Zookeeper
现在master1上,把Zookeeper的安装包上传。然后解压。
1
2
3
[root@master1 ~]# tar xzf zookeeper-3.4.7.tar.gz -C /usr/develop/
[root@master1 ~]# rm zookeeper-3.4.7.tar.gz
rm: remove regular file `zookeeper-3.4.7.tar.gz'? y
随后进入Zookeeper目录,修改配置文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[root@master1 ~]# cd /usr/develop/zookeeper-3.4.7/
[root@master1 zookeeper-3.4.7]# cp conf/zoo_sample.cfg conf/zoo.cfg
[root@master1 zookeeper-3.4.7]# vim conf/zoo.cfg
dataDir=/usr/develop/zookeeper-3.4.7/tmp
clientPort=2181
server.1=192.168.117.52:2888:3888
server.2=192.168.117.53:2888:3888
server.3=192.168.117.54:2888:3888
autopurge.purgeInterval=1
tickTime=2000
initLimit=10
syncLimit=5
增加myid:
1
2
3
4
[root@master1 zookeeper-3.4.7]# mkdir tmp
[root@master1 zookeeper-3.4.7]# echo 1 > tmp/myid
[root@master1 zookeeper-3.4.7]# cat tmp/myid
1
随后将配置好的zookeeper发送到master2和master3上
1
2
3
4
[root@master1 zookeeper-3.4.7]# cd ..
[root@master1 develop]# tar zcf zookeeper-3.4.7.tar.gz zookeeper-3.4.7/
[root@master1 develop]# scp zookeeper-3.4.7.tar.gz root@master2:/usr/develop
[root@master1 develop]# scp zookeeper-3.4.7.tar.gz root@master3:/usr/develop
随后到master2和master3上解压zookeeper,修改myid:(下面仅演示master2,master3操作类似)
1
2
3
4
5
6
[root@master2 ~]# cd /usr/develop/
[root@master2 develop]# tar xzf zookeeper-3.4.7.tar.gz -C ./
[root@master2 develop]# cd zookeeper-3.4.7
[root@master2 zookeeper-3.4.7]# echo 2 > tmp/myid
[root@master2 zookeeper-3.4.7]# cat tmp/myid
2
分别在三台机器启动Zookeeper服务:(下面仅演示master1)
1
2
3
4
[root@master1 zookeeper-3.4.7]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/develop/zookeeper-3.4.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
启动三个Zookeeper后,我们可以在三台机器看到机器的角色:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[root@master1 zookeeper-3.4.7]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/develop/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: follower
[root@master2 zookeeper-3.4.7]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/develop/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: leader
[root@master3 zookeeper-3.4.7]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/develop/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: follower
配置Hadoop
安装好ZooKeeper后。需要配置Hadoop集群。
在master1上配置,随后把配置文件拷贝到其它机器即可。
core-site.xml文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<configuration>
<!--用来指定hdfs的老大,ns为固定属性名,表示两个namenode-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/develop/hadoop-2.7.1/tmp</value>
</property>
<!--执行zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,master3:2181</value>
</property>
</configuration>
hdfs-site.xml文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
<configuration>
<!--执行hdfs的nameservice为ns,和core-site.xml保持一致-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--ns下有两个namenode,分别是nn1,nn2-->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master1:9000</value>
</property>
<!--nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master1:50070</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>master2:9000</value>
</property>
<!--nn2的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>master2:50070</value>
</property>
<!--指定namenode的元数据在JournalNode上的存放位置,这样,namenode2可以从jn集群里获取
最新的namenode的信息,达到热备的效果-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485;slave3:8485/ns</value>
</property>
<!--指定JournalNode存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/develop/hadoop-2.7.1/journal</value>
</property>
<!--开启namenode故障时自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置切换的实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--配置隔离机制的ssh登录秘钥所在的位置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置namenode数据存放的位置,可以不配置,如果不配置,默认用的是core-site.xml里配置的hadoop.tmp.dir的路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/develop/hadoop-2.7.1/tmp/namenode</value>
</property>
<!--配置datanode数据存放的位置,可以不配置,如果不配置,默认用的是core-site.xml里配置的hadoop.tmp.dir的路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/develop/hadoop-2.7.1/tmp/datanode</value>
</property>
<!--配置block副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml文件
1
2
3
4
5
6
7
8
9
<configuration>
<!--指定mapreduce运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
<configuration>
<!-- 开启YARN HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定两个resourcemanager的名称 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置rm1,rm2的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master3</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--执行rm恢复机制实现类-->
<!-- 配置rm1,rm2的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master3</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--执行rm恢复机制实现类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置zookeeper的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master1:2181,master2:2181,master3:2181</value>
<description>For multiple zk services, separate them with comma</description>
</property>
<!-- 指定YARN HA的名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
<!--指定yarn的老大 resoucemanager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master1</value>
</property>
<!--NodeManager获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
随后在etc/hadoop下修改slaves文件,用来标明slaves的主机:
1
2
3
4
[root@master1 hadoop-2.7.1]# vim etc/hadoop/slaves
slave1
slave2
slave3
把配置好的etc文件打包,发送到其余的节点上并解压(下面仅演示master1到master2)
1
2
3
4
5
6
[root@master1 hadoop-2.7.1]# tar czf etc.tar.gz etc/
[root@master1 hadoop-2.7.1]# scp etc.tar.gz root@master2:/usr/develop/hadoop-2.7.1
[root@master2 hadoop-2.7.1]# tar xzf etc.tar.gz -C ./
[root@master2 hadoop-2.7.1]# rm etc.tar.gz
rm: remove regular file `etc.tar.gz'? y
随后在每个节点下创建journal, tmp/namenode, tmp/datanode(下面仅演示master1)
1
2
[root@master1 hadoop-2.7.1]# mkdir journal
[root@master1 hadoop-2.7.1]# mkdir -p tmp/namenode tmp/datanode
以上,就大体将集群的Hadoop环境配置完毕了。
启动集群
如果以上配置都没有问题,那么就可以启动Hadoop集群了。
格式化Zookeeper
首先,需要格式化Zookeeper,在Zookeeper的Leader上(此时是master2)执行:
1
2
3
4
[root@master2 hadoop-2.7.1]# hdfs zkfc -formatZK
...
18/03/31 18:04:21 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns in ZK.
...
出现Successfully,表示格式化成功。不成功请查看ZK和Hadoop配置是否正确,ZK服务是否启动。
启动Journal Node
启动journal集群(slave1,slave2,slave3):
1
2
3
4
5
6
7
8
9
[root@slave1 hadoop-2.7.1]# jps
2303 Jps
[root@slave1 hadoop-2.7.1]# hadoop-daemons.sh start journalnode
slave1: starting journalnode, logging to /usr/develop/hadoop-2.7.1/logs/hadoop-root-journalnode-slave1.out
slave3: starting journalnode, logging to /usr/develop/hadoop-2.7.1/logs/hadoop-root-journalnode-slave3.out
slave2: starting journalnode, logging to /usr/develop/hadoop-2.7.1/logs/hadoop-root-journalnode-slave2.out
[root@slave1 hadoop-2.7.1]# jps
2374 JournalNode
2408 Jps
看到JournalNode监听服务表示启动成功。
只需要在一个slave执行这个命令,其余slave的Journal会自动启动(保守起见,你可以去其余机器看一下)。
启动NameNode
在master1上,格式化NameNode:
1
2
[root@master1 hadoop-2.7.1]# hadoop namenode -format
...
随后在master1上启动NameNode:
1
2
3
4
5
6
[root@master1 hadoop-2.7.1]# hadoop-daemon.sh start namenode
starting namenode, logging to /usr/develop/hadoop-2.7.1/logs/hadoop-root-namenode-master1.out
[root@master1 hadoop-2.7.1]# jps
7585 QuorumPeerMain
8119 Jps
8045 NameNode
在master2上启动热备份:
1
2
3
4
[root@master2 hadoop-2.7.1]# hdfs namenode -bootstrapStandby
...
18/03/31 18:16:55 INFO common.Storage: Storage directory /usr/develop/hadoop-2.7.1/tmp/namenode has been successfully formatted.
...
在master2上启动NameNode(Stand-by):
1
2
3
4
5
6
[root@master2 hadoop-2.7.1]# hadoop-daemon.sh start namenode
starting namenode, logging to /usr/develop/hadoop-2.7.1/logs/hadoop-root-namenode-master2.out
[root@master2 hadoop-2.7.1]# jps
2792 Jps
2718 NameNode
2415 QuorumPeerMain
启动DataNode
在slave1,2,3上执行下面的命令,启动DataNode:
1
2
3
4
5
6
[root@slave1 hadoop-2.7.1]# hadoop-daemon.sh start datanode
starting datanode, logging to /usr/develop/hadoop-2.7.1/logs/hadoop-root-datanode-slave1.out
[root@slave1 hadoop-2.7.1]# jps
2561 Jps
2482 DataNode
2374 JournalNode
启动ZKFC
在master1,2上运行下面的命令:
1
2
3
4
5
6
7
[root@master1 hadoop-2.7.1]# hadoop-daemon.sh start zkfc
starting zkfc, logging to /usr/develop/hadoop-2.7.1/logs/hadoop-root-zkfc-master1.out
[root@master1 hadoop-2.7.1]# jps
8209 DFSZKFailoverController
7585 QuorumPeerMain
8278 Jps
8045 NameNode
这个进程控制NameNode的接替工作。也就是如果master1宕机了,让master2接替master1的工作。
启动Yarn
在master1上启动ResourceManager:
1
2
3
4
5
6
7
8
9
10
11
12
[root@master1 hadoop-2.7.1]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/develop/hadoop-2.7.1/logs/yarn-root-resourcemanager-master1.out
slave3: starting nodemanager, logging to /usr/develop/hadoop-2.7.1/logs/yarn-root-nodemanager-slave3.out
slave2: starting nodemanager, logging to /usr/develop/hadoop-2.7.1/logs/yarn-root-nodemanager-slave2.out
slave1: starting nodemanager, logging to /usr/develop/hadoop-2.7.1/logs/yarn-root-nodemanager-slave1.out
[root@master1 hadoop-2.7.1]# jps
8336 ResourceManager
8209 DFSZKFailoverController
7585 QuorumPeerMain
8602 Jps
8045 NameNode
这样,slave1,2,3的NodeManager会自动启动:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
[root@slave1 hadoop-2.7.1]# jps
2482 DataNode
2374 JournalNode
2601 NodeManager
2714 Jps
[root@slave2 hadoop-2.7.1]# jps
2449 DataNode
2307 JournalNode
2568 NodeManager
2681 Jps
[root@slave3 hadoop-2.7.1]# jps
2338 JournalNode
2565 NodeManager
2678 Jps
2446 DataNode
在master3上启动ResourceManager(Stand-by):
1
2
3
4
5
6
[root@master3 hadoop-2.7.1]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /usr/develop/hadoop-2.7.1/logs/yarn-root-resourcemanager-master3.out
[root@master3 hadoop-2.7.1]# jps
2170 ResourceManager
2204 Jps
2031 QuorumPeerMain
以上,整个集群启动完毕。
测试集群
在浏览器查看集群的master节点的50070端口,可以通过可视化界面来查看集群的状态。
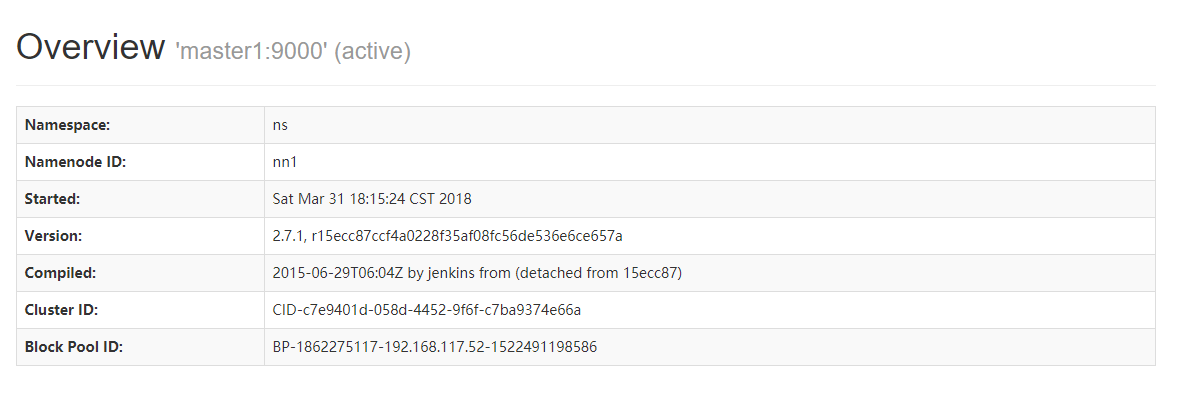
下面是我这个集群的master1,2的网页截图。
master1状态
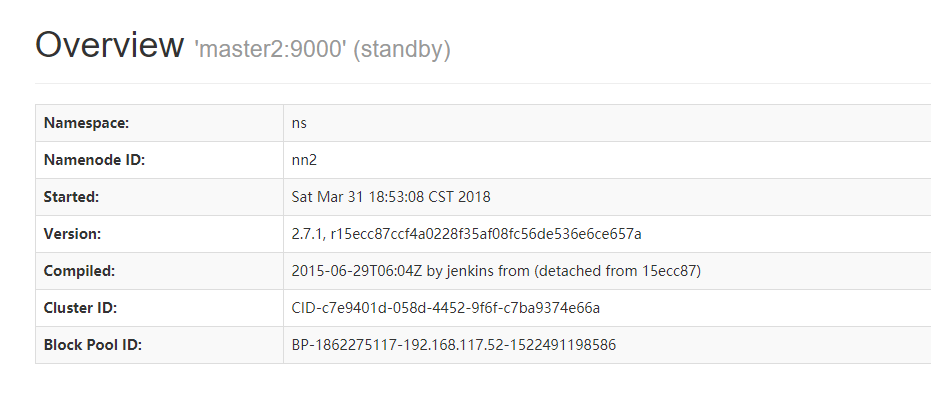
master2状态
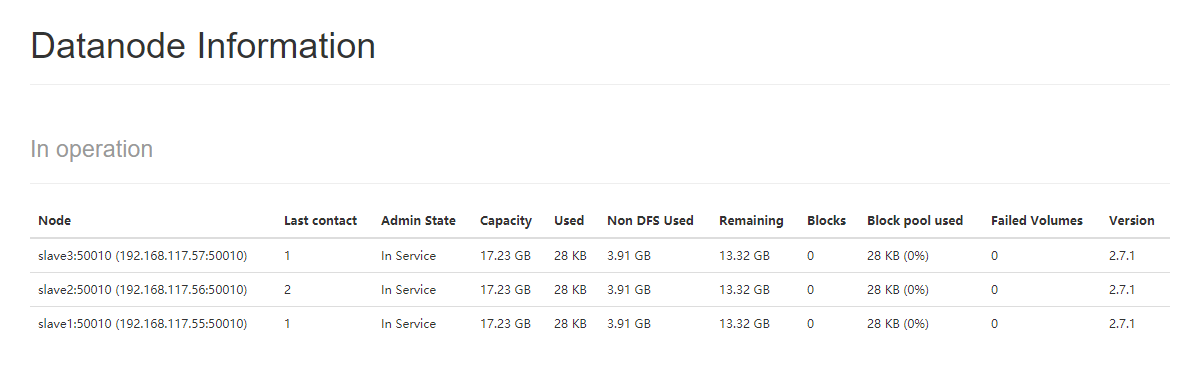
DataNodes状态
下面我们看看master1故障时master2会不会更替master1的位置。
停止master1的NameNode:
1
2
3
4
5
6
7
[root@master1 hadoop-2.7.1]# hadoop-daemon.sh stop namenode
stopping namenode
[root@master1 hadoop-2.7.1]# jps
8336 ResourceManager
8209 DFSZKFailoverController
7585 QuorumPeerMain
8835 Jps
随后,我们再访问master2:

我们看到master2变为了active。这就是顶替了master1的位置。
那么我们再启动master1:
1
2
3
4
5
6
7
8
[root@master1 hadoop-2.7.1]# hadoop-daemon.sh start namenode
starting namenode, logging to /usr/develop/hadoop-2.7.1/logs/hadoop-root-namenode-master1.out
[root@master1 hadoop-2.7.1]# jps
8336 ResourceManager
8209 DFSZKFailoverController
7585 QuorumPeerMain
8948 Jps
8868 NameNode
再看master1:

可见恢复的master1又变成了standby。
通过8088端口,可以查看Yarn的状态。注意只能查看active的端口。
关掉master1的ResourceManager,master3的ResourceManager可以马上工作,这里不再演示。
如果测试没问题,表示整个集群工作正常了。